

Simform
LLaMA Model Minimum VRAM Requirement Recommended GPU Examples RTX 3060 GTX 1660 2060 AMD 5700. Llama2 7B-Chat on RTX 2070S with bitsandbytes FP4 Ryzen 5 3600 32GB RAM Completely loaded on VRAM 6300MB took 12 seconds to. Llama 2 The next generation of our open source large language model Hardware requirements vary based on latency throughput and cost. How much RAM is needed for llama-2 70b 32k context. Get started developing applications for WindowsPC with the official ONNX Llama 2 repo here and ONNX runtime here Note that to use the ONNX Llama..
. Llama 2 encompasses a range of generative text models both pretrained and fine-tuned with sizes from 7 billion to 70 billion parameters. A self-hosted offline ChatGPT-like chatbot powered by Llama 2 100 private with no data leaving your. The main goal of llamacpp is to enable LLM inference with minimal setup and state-of-the-art performance on a wide variety of hardware -. Result Run the Python script You should now have the model downloaded to a directory called..
Medium
This repo contains GPTQ model files for Meta Llama 2s Llama 2 7B Chat Multiple GPTQ parameter permutations are provided See Provided Files below for details of the options. Web Our fine-tuned LLMs called Llama-2-Chat are optimized for dialogue use cases Llama-2-Chat models outperform open-source chat models on most benchmarks we tested and in our. Web from transformers import AutoTokenizer pipeline logging from auto_gptq import AutoGPTQForCausalLM BaseQuantizeConfig model_name_or_path TheBlokeLlama-2-7b-Chat-GPTQ. Web We then ask the user to provide the Models Repository ID and the corresponding file name If not provided we use TheBlokeLlama-2-7B-chat-GGML and llama-2-7b. Web Llama-2-70B-chat-GGUF Q4_0 with official Llama 2 Chat format Gave correct answers to only 1518 multiple choice questions Often but not always acknowledged data input with..
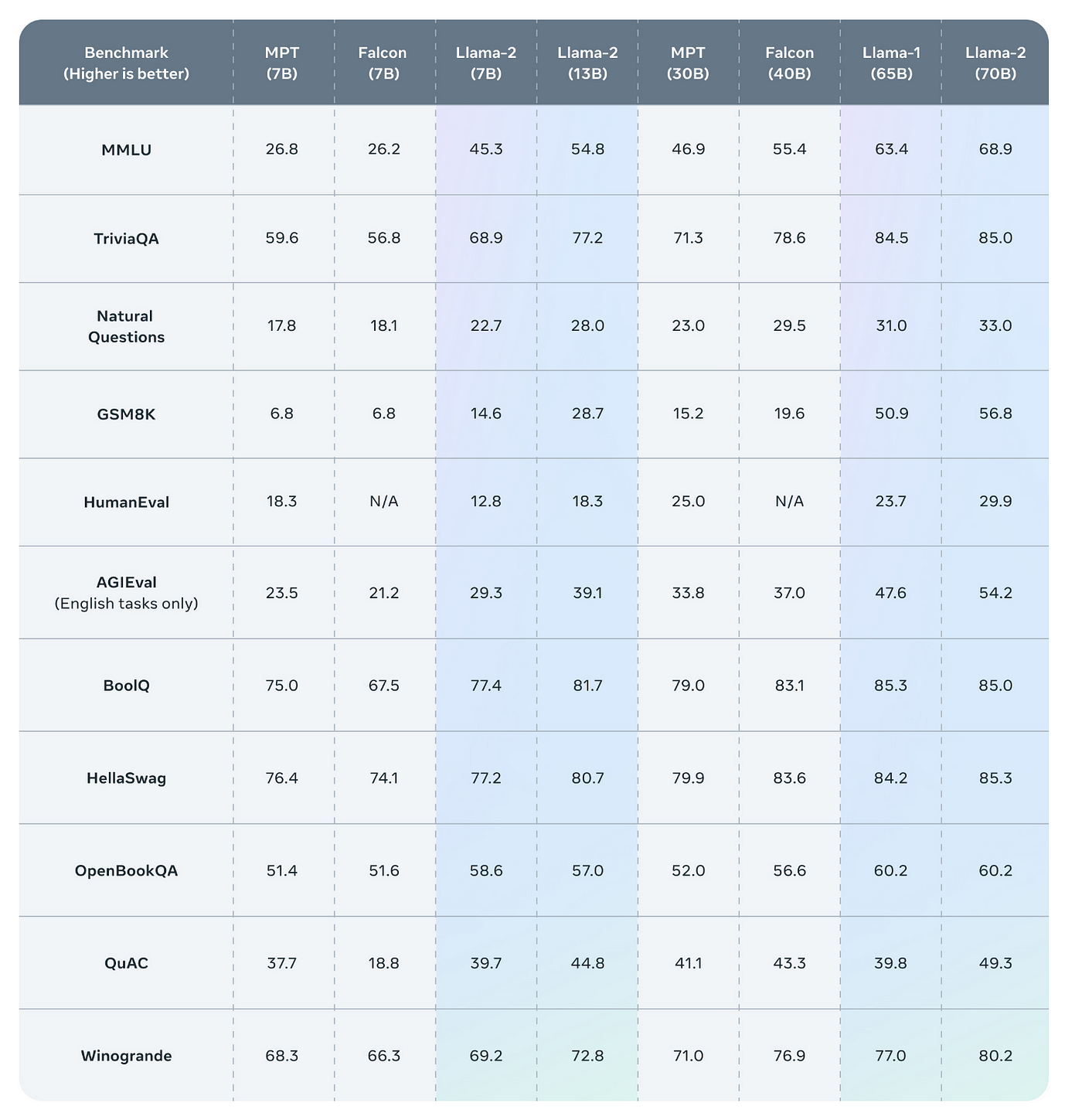
Result Models as a Service MaaS with Llama 2 and Microsoft Azure Inference and Fine-Tuning for Llama 2 on Microsoft Azure Cloud Platform. Offers serverless GPU-powered inference on Cloudflares global network Its an AI inference service enabling developers to. Result The tutorial provided a comprehensive guide on fine-tuning the LLaMA 2 model using techniques like QLoRA PEFT and SFT to overcome memory and. Result Image from Llama 2 - Resource Overview - Meta AI Llama 2 outperforms other open language models on many external benchmarks including. ..

Comments